
So we are all happy to use LLM AI’s to help us run our lives more efficiently, but I was wondering how do we test the software to make sure it is working correctly?
I found this information on how to attack the Miessler website AI programs from a year ago:
There also was a paper written on the many facets of cybersecurity and AI programs… called:
From ChatGPT to ThreatGPT: Impact of Generative AI in Cybersecurity and Privacy at cornell arxiv,org weblink.
https://arxiv.org/abs/2307.00691
This is the most interesting diagram…
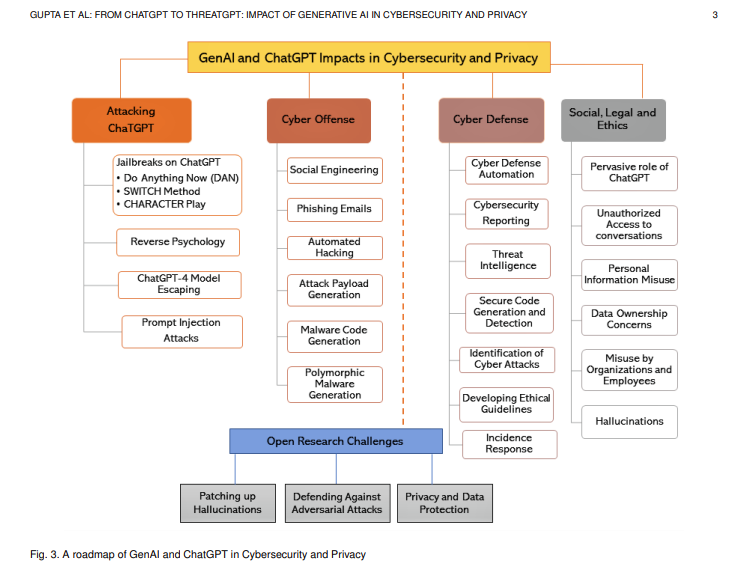
Here is the SCMagazine 7 AI threats and what to do
The list of AI threats facing security teams today has grown fast. Here are the most common today:
- Prompt Injection: Where attackers manipulate an AI model’s output by embedding specific instructions in the prompt, similar to SQL injection in databases.
- Prompt Leaking: A subset of prompt injection designed to expose a model’s internal workings or sensitive data, posing risks to data privacy and security.
- Data Training Poisoning: Involves corrupting a machine learning model’s training dataset with malicious data to influence its future behavior, akin to an indirect form of prompt injection.
- Jailbreaking Models: Refers to bypassing the safety and moderation features of AI chatbots, such as ChatGPT or Google’s Bard, using prompt injection techniques that resemble social engineering.
- Model Theft: The unauthorized replication of an AI model by capturing a vast number of input-output interactions to train a similar model, which can lead to intellectual property theft.
- Model Inversion Attacks and Data Extraction Attacks: An AI model gets queried with crafted inputs to reconstruct or extract sensitive training data, threatening confidentiality.
- Membership Inference Attacks: Designed to determine if specific data was used in training a model by analyzing its responses, potentially breaching data privacy.
Notice that in both the academic paper and the SCMagazine article include Jailbreaks and Prompt injection. The idea in all the possible attack methods is to get the AI to reveal more information than it should reveal as well as changing the possible answers by affecting the data the AI uses.
How would one go about and actually test these AI LLM programs?
One has to have a set of questions to use and a set of words to use to see how the AI responds. Of course these words should change with each AI program and task, thus being a fluid test.
The real question of testing would be what would constitute a good or bad test? Of course if one finds privacy violations or actual errors those are easy to declare the test successful in finding the flaws. But what if nothing has been found ‘so far’ what would constitute a reasonable closure of the test and declare the AI ‘safe’?
Obviously there needs to be a way to test the AI program to reduce the risk of failure (which include jailbreaking and prompt injection as well as whatever else may be needed. Ideally one needs a continual method to test the AI eventually, or at least a minimal time or two.
Here is also an interesting thoughts of the future of AI which could be called AGI(Artificial General intelligence) or ASI(Artificial Super Intelligence) the following image is from Leopold’s X page image. OOM= Orders Of Magnitude
Also check his page at Situationalawareness.ai

I know I am going to a completely different topic, but Leopold Aschenbrenner (Leopold was interviewed in this youtube video“Trillion$Cluster”) has started thinking about the future direction of AI which he calls AGI(Artificial General intelligence) or ASI(Artificial Super Intelligence). This AI is OOM Order Of Magnitude better than what we currently have. But the thought is 2027 (or shortly thereafter) could see an AI that may not be self aware like in the movies, but the program may understand how to model the world just well enough to make a decent approximation of how the world works. Of course this kind of capability has many meanings, but as I always say we typically do not build security into the systems we initially build. Which is why the programs can be jailbroken and prompt injected today. My fervent wish is to include some cybersecurity in this future Trillion-dollar AI computer cluster by 2027 or beyond.
The interesting thing with predictions 3 to 4 years from now is that they will most likely be wrong, as 18 months ago we would not have thought much about ChatGPT2.0 as it was not capable of much. The initial exponential increase is not that obvious (i.e. going from 2 to 4 to 8 to 16 is not that obvious but when we are at 256 , 512, 1024, 2048, now the next upgrade might be shaking some foundations of other businesses).
Of course there is another aspect to predictions of exponential growth, maybe the growth of 16MB to 32MB to 64MB and higher may not work out exactly as prescribed since some unforeseen problem may not be a doubling phenomenon as before, and may be a 1.5x or lower, which admittedly is still good growth.
Unmitigated growth may not be constant forever, but what should be is the testing of this new program. The Trillion Dollar cluster may be inevitable, and the timing may not be important. What should be important is developing ways to test the program/cluster etc.
The above image is from a long time ago (December 3, 2015 post at oversitesentry.com)With one of my old logos…
As you can see I have been focusing on this topic for a while now (almost 10 years online – and before that offline).
Do not forget our adversaries are also developing strategies:
The idea: some input, one must inspect it and then review, feed it back, and do it again. it is called a system engineering basic feedback loop. Contact to learn what I am doing to review AI programs…